本文共 4818 字,大约阅读时间需要 16 分钟。
一、Truncate简介
无数次事故告诉我们,Truncate是一项很危险的动作。一不小心搞错,就会带来毁灭性的打击。我们都知道当Truncate命令发起之后,Oracle实际上并没有在删除底层数据块上的数据,而是要等到重用的时候才会把这一部分数据回收,于是这给了我们一个能够恢复数据库的机会。
二、知己知彼
对于Truncate单表来说,其实就相当于摧毁我们的一个段,我们数据库中的物理结构是由段区块三个构成的。首先我们要最需要了解的就是一张“图谱”?图谱是什么?就是一个段的组成结构,而最能表现段的构成的就是一个三级位图块的结构图。
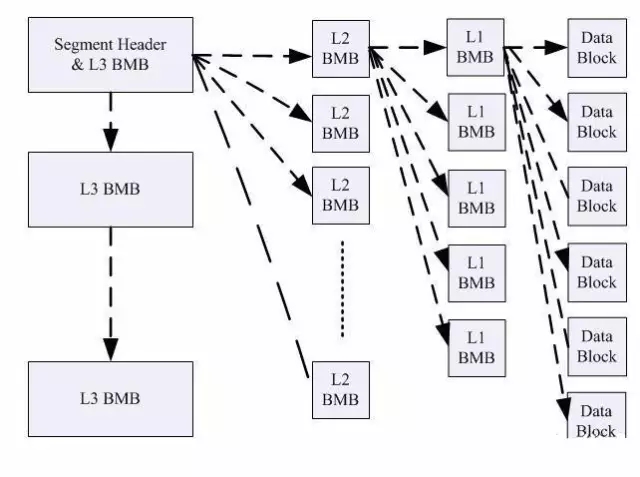
我们可以看到一个段最先是由段头块构成的,段头其实就是第1个L3块,只有当这些无法记录下的时候,才会产生第2个L3级块,不过这种情况非常少见,段头块指向了若干的L2位图块,每个L2位图块又指向了若干L1位图块,L1位图块则指向了真正的数据块。
1.建立实验环境所需要的表
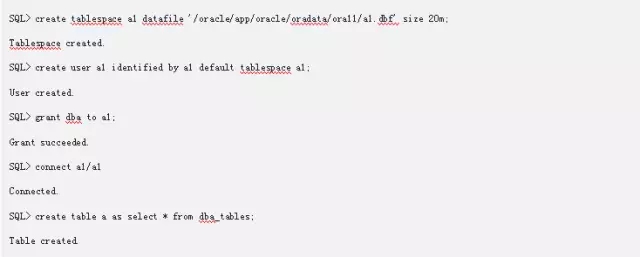
实验环境建立完成之后,我们就需要摸清楚我们的这个段A的位图及数据块分布情况,我们不直接从视图里面查,这里我们考虑需要通过bbed的方式从数据块中获取位图及数据块分布情况。
2.段头块/L3位图块指向了哪些L2位图块
段由哪些区间构成?这个信息我们需要从段头块中获取出来。当你创建一个段后,即使你没有往里面插入任何数据,系统也是会预先分配一些区给你的。所以段头块是那个块,我们可以通过dba_segments查询出来。就算truncate了这个段,我们仍然能够从dba_segments中查询到段头的信息。

找到了段头块,我们就可以用bbed挖掘下信息。
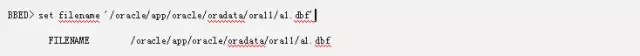

这里我们可以看到段头块的第一个offset是23。那么我们的段头块指向的L2位图块在offset 5192的位置。这里请记住段头块的标示是23。
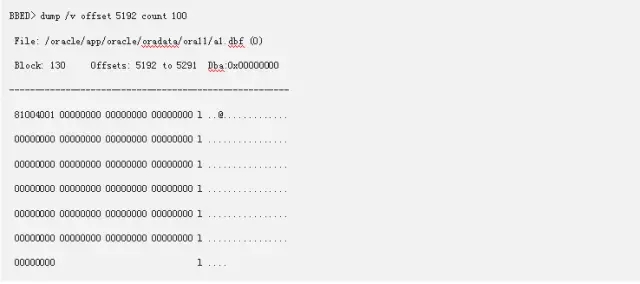
从这里我们既可以找到我们的L2位图块,81004001,这里只有1个L2块,因为后面都是00000000(空),因为涉及到操作系统字节序的问题,这里需要转换换成01400081。转换后我们可以使用下列查询找到文件号和块号。
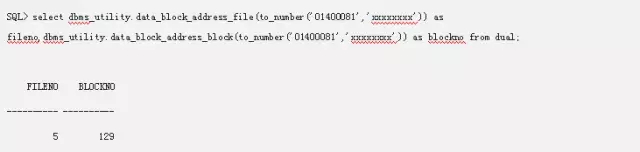
3.L2位图块指向了哪些L1位图块
接下来我们可以继续读我们的L2位图块来寻找我们的L1位图块。可以看到L2的第一个offset是21。请记住L2位图块的标示是21。

L2指向L1数据块的位置从offset 116开始。到哪儿结束需要看后面有没有00000000(空)
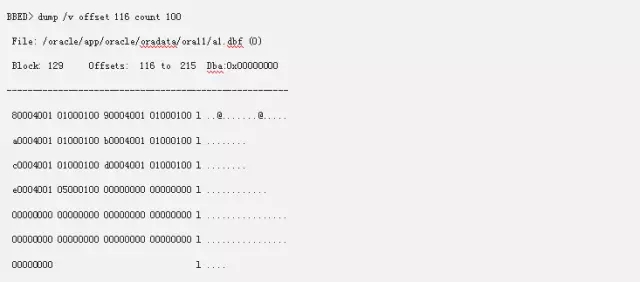
从dump出来的地方我们来看,前面是一个地址,后面跟着是01000100,比较规律,大概7组之后就变成00000000(空)了。 跟上面一样因为字节序的问题,这里我们需要将80004001转换成01400080。然后我们通过下列查询得到了区块的位置。而后面的01000100,前面的01则这个L1下面的块全部填满,无空数据块,后面的01则代表这个块是instance 1产生的。而最后的一个05000100,05则代表着这个L1下面还有空块,可以插入。而后面的01我们说过代表着是instance。如果这个系统是个rac的系统,节点2也插入了数据,那么这里就会显示05000200。


通过上述查询,我们找到了7个L1块的信息。
4.L1位图块指向了哪些数据块
前面我们查到了我们的L2块上指向的L1块,并且清楚的知道哪个L1下面是满的,哪个L1下面还有空闲块。我们就从拿最后一个有空闲块的L1位图块进行分析。

可以看到L1的第一个offset是20。请记住L1位图块的标示是20。
L1指向数据块的位置从offset 204开始。到哪儿结束需要看后面有没有00000000(空)

大家可以看到这里的值是e0004001,08000000,00000000,下一组值是e8004001,08000000,08000000,然后面就是00000000(空)。
这两个的意思是告诉我们L1指向数据块的起始位置,比如e0004001,就是文件5,块224,也就是它自己本身。08000000就代表着这个块后面的连续7个块都是的。而e8004001,08000000,08000000,就是文件5,块232,08000000就代表着这个块后面的连续7个块也是的。而最后一个08000000则代表着offset,这里我们可以不用去管它。所以这里我们就能够知道我们的L1块下面具体的数据块有:224(它本身),225,226,227,228,229,230,231,232,233,234,235,236,237,238,239。我们来用下列语句查证一下。

可以看到223后面直接就是225,直接此处跳空,这是因为我们的224是L1位图块,后面紧跟着我们刚刚说的225,226,227,228,229,230,231,232,233。但是问题是,这里看不到后面的234到239?这是因为234到239还是空闲没有格式化过的块,但是它已经被L1锁定了。那么我们的L1能不能看到这些情况呢?我们可以观察offset 396。

这里可以看到的是11111111,11000000。那么这个代表什么意思呢?如果这个块是full的话,就是1,是unformatted的话就是0,正好和我们前面看到的吻合。
三、Truncate如何恢复?
1.Data Object ID恢复
前面我们介绍了我们的段的组成形式,这里来总结一下,首先是段头块,它指向了L2块,L2块指向了L1块,而L1块则指向了我们真实的物理数据块。试着想想,如果我们发起truncate之后,Oracle会怎么做?
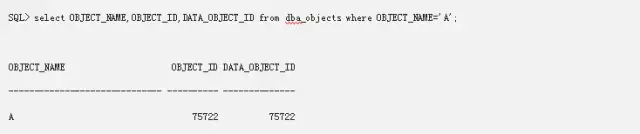
我们先来看一下对象,当我们创建对象的之后,OBJECT_ID和data_object_id都会是一样的,但是当我们发生truncate之后,我们的object_id不会变,而data_object_id则会变掉。
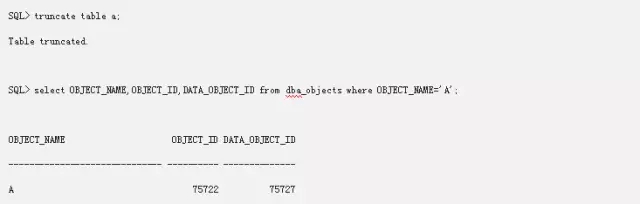
这里可以看到我们Truncate表之后,data_object_id从75722变成了75727。我们分别看一下我们的段头块,L2位图块,L1位图块,数据块,这个ID是否有变化。分别从检查块130,129,224,225






通过对各个块的dump,发现段头和L2位图块的data_obj_id已经发生了改变,从ca270100变成了cf270100,而只有第一个L1发生了变化,数据块则没有发生改变。
那我们是不是把data_obj_id修改回来就能够恢复数据呢?


这里还需要修改数据字典,否则会报错。



2.段头高水位信息恢复
修改了这些东西后,我们会发现数据还是没有。我们还需要修改一些信息。一个很重要的信息就是段头上的高水位信息。在Truncate之前,段头上会记载。前面我们在讲L1块的时候说过:
可以看到223后面直接就是225,直接此处跳空,这是因为我们的224是L1位图块,后面紧跟着我们刚刚说的225,226,227,228,229,230,231,232,233。但是问题是,这里看不到后面的234到239?这是因为234到239还是空闲没有格式化过的块,但是它已经被L1锁定了。
所以我们现在的高水位的块是234,一般做全表扫描的查询就会查高水位以下(234)的块。我们来看下我们现在的高水位。
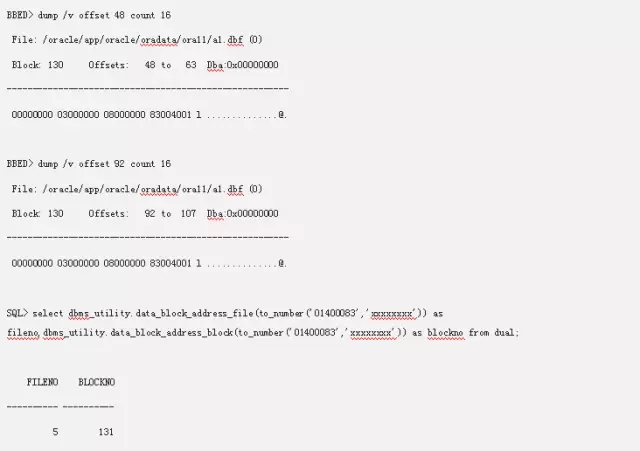
注意看这里的高水位是83004001,转换成文件号和块号,刚好是文件5块131。而前面的00000000,03000000,则代表着是扩展0,block 3,代表着高水位的位置。刚好是第一个extent的第三个块。128是L1,129是L2,130是段头块。而131则是第一个可以使用的数据块。所以这里记录了extent 0,block为3则代表了文件5的131号块。而08000000则代表了extent的大小,我们每个extents是由8个块组成的。
那在truncate之前,我们的高水位的块是文件5块234,我们从块128开始,每8个块是一个extent,234是第14个extent的第三个块。后面的6个块是没有插入数据的空块。这个在前面我dump 最后一个L1块得知。回顾一下,这里下面的块状态显示11111111 11000000。
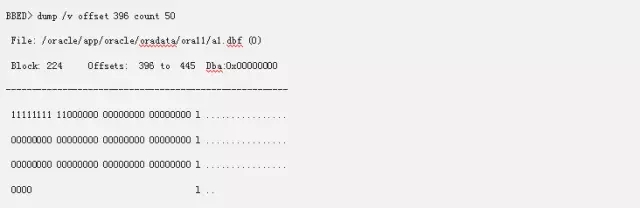
所以我们这个地方要把高水位从00000000 03000000 08000000 83004001修改成0d000000 02000000 08000000 ea004001。0d000000代表13,表明是第十四个扩展,02000000代表02,表明是第三个块开始,而08000000还是一样代表着这个扩展是8个块的大小,而ea004001则代表着文件5块234。



修改完成之后,刷新buffer cache,然后重新查询。

3.Extents信息恢复
可以看到数据量不对,这是因为我们Truncate之后,在段头上只剩下了一个Extent的信息。而我们的Extents是有14个的,这需要我们在修改如下几个地方。Offset 264代表着我们Extents的数量,,这里修改成0e代表了14个extents。

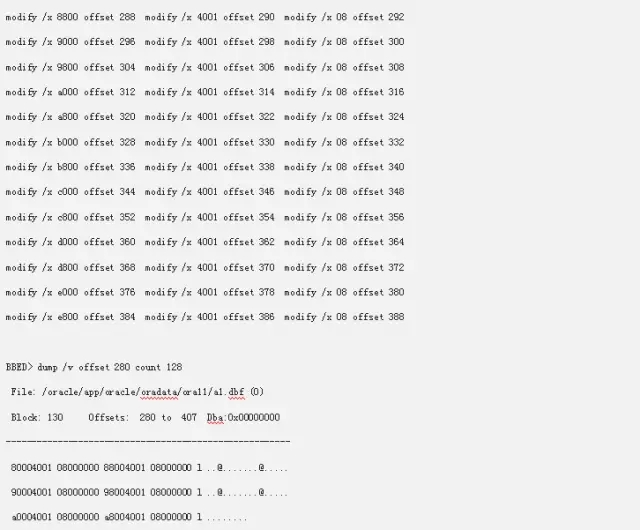
修改完Extents的数量之后,还需要添加对应的Extents Map的信息。因为我们的Extents Map信息也被删除了。从我们的offset 280开始。

80004001 08000000这个Extents是我们第一个Extents。代表了文件5的块128。我们可以依次类推下列的信息出来。而08000000则代表有8个数据块构成一个Extents。

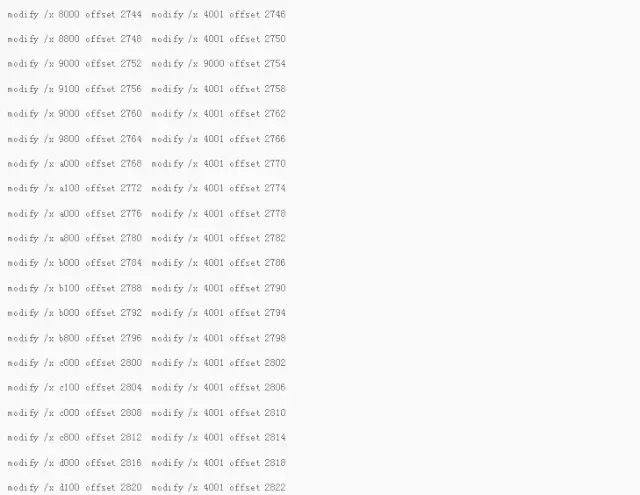
当然这些Extents Map修改完成之后,我们还需要在添加Auxillary Map。那什么是辅助的Map呢?我们从Offset 2736开始。
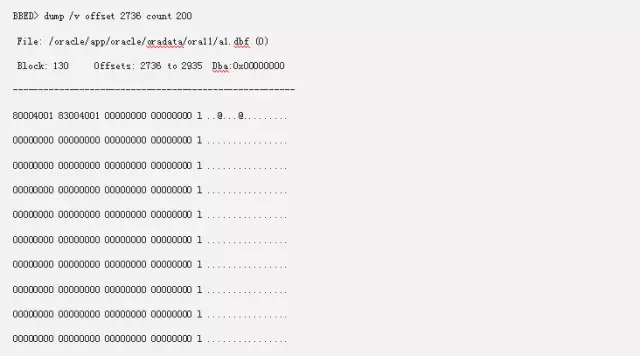
这里的80004001 83004001,代表这Extents中,L1块的地址和Data Block的地址,可以看到在Extents 1上面,它的L1块是128,而数据块是从131开始的。因为我们的129是L2,130是段头。所以下面我们构造其他的数据的时候,我们也要遵循这个规律。我们的Extents 2,它的L1还是128块,但是它的数据块确是从136开始的。而Extents 3,它的L1就是第二个L1块,也就是144,而它的数据块的开始则是从145开始的。依次类推下去。结果如下:
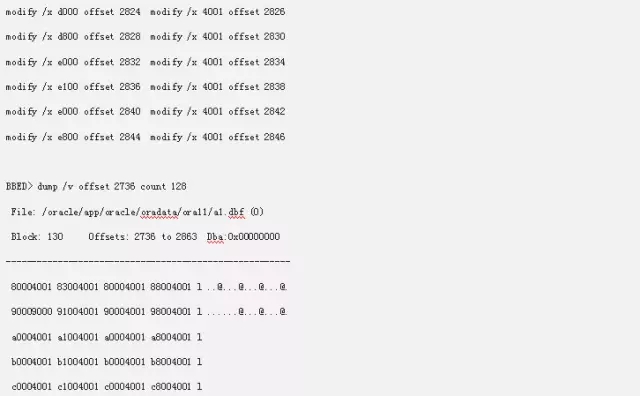

修改完成这些后,我们就能够查到我们全部的数据了。

此时我们切勿执行一些其他的操作,应该尽快的使用CTAS的方式将这个表进行备份或者是导出。因为段头块L2和L1的信息还一些是没有修改的。

至此,Truncate恢复完成。仔细的研究你才会发现,其实最重要的是摸清楚整个段的构造情况,只要你对整个段的构造情况,了若指掌,基本上恢复是很简单的。
所以对于Truncate恢复,我总结以下步骤:
1. 遍历所有数据文件的数据块,寻找offset 1是23的,23代表段头块,同时还要和相应的Data Object Id相同的,这个需要检索offset 272的位置。
2. 找到了段头块,我们就可以通过offset 5192寻找到我们的L2块。
3. 找到了L2块,我们就可以通过offset 116找到所有的L1块。找到了L1块,我们就等于找到了数据块。
4. 至此,我们就可以开始反向的构造段头块。
5. 修改段头块、L2块和第一个L1块的Data Object Id.,同时在修改数据字典。
6. 修改段头块的高水位信息。当然这里的高水位块的辨别,一定会是在最后一个Extents上,你可以设置到最后一个Extnets的最后一个块,这个信息的准备性其实无所谓,全表扫描的时候它一定会扫描这个块下面所有的块。
7. 修改段头上的Extents信息。
以上步骤完成之后,数据就可以查到,首要步骤就是CTAS重建该对象。
本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2015-12-01
转载地址:http://zggjx.baihongyu.com/